PDF(976 KB)
PDF(976 KB)

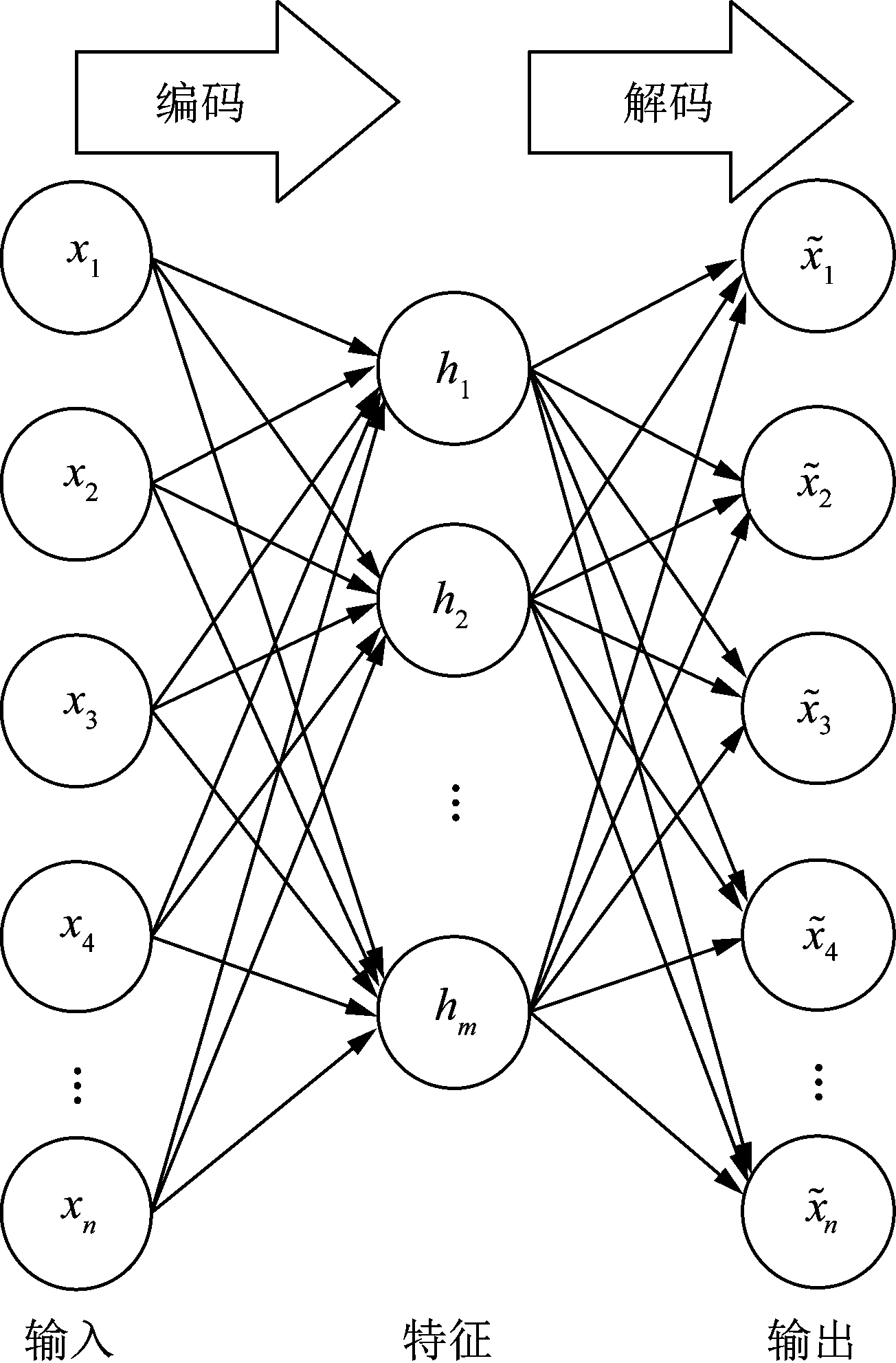
Research on Similarity Matching of Power Network Operation Section Applying Stacked Automatic Encoder
WANG Tieqiang, LU Peng, CAO Xin, YANG Xiaodong, WANG Wei, Lü Hao, FENG Chunxian, TIAN Chao, SHI Haoyan, LIANG Haiping
Electric Power Construction ›› 2021, Vol. 42 ›› Issue (1) : 117-124.
PDF(976 KB)
PDF(976 KB)
Research on Similarity Matching of Power Network Operation Section Applying Stacked Automatic Encoder
 ({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}
({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
/
| 〈 |
|
〉 |